Model Monitoring Using SageMaker and CDK

Machine learning techniques are becoming increasingly popular, and you can find them almost everywhere. At least, in all areas dealing with large volumes of data such as medicine, signal/image processing, fintech and manufacturing. Machine learning algorithms mimic human ways of learning. They can be trained to make classifications or predictions without being explicitly programmed. This makes them particularly useful in speech recognition. In one of our projects, we helped to automate building, training, deployment and monitoring of machine learning models for transcription and text processing using Amazon SageMaker and AWS Cloud Development Kit (CDK). The accuracy of the machine learning model depends on multiple parameters including the quality of incoming data that can be different from the data used for model training due to data schema changes, type mismatch, missing data or invalid data values. One of our tasks was to ensure the stability of prediction by implementing a SageMaker monitoring job for regular checks of data quality. This was done using SageMaker Model Monitor. More information about model monitoring can be found in Stephen Oladele’s excellent blog post. Here, I describe how to build a scheduled data quality monitoring job using Amazon SageMaker and CDK.
SageMaker Model Monitor Types
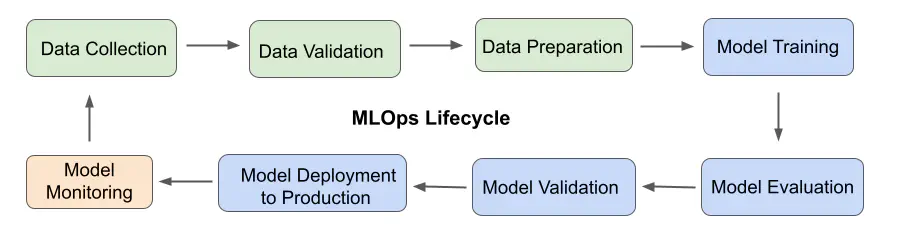
The diagram below shows the main steps of MLOps lifecycle. Model monitoring is usually performed after data is cleaned, validated and preprocessed, and the model is trained, tested and deployed into production.
The behavior of machine learning applications depends on the data used for the model training as well as on real-life data streaming into the application. The machine learning models can degrade over time due to:
- data quality issues (data schema changes, missing/invalid data, type mismatch, etc.),
- changes in distribution of real-life data compared to the training data,
- feature drift due to extreme or anomalous events,
- real-world changes resulting in differences between learned relationships/patterns and the real ones.
Regular model monitoring allows us to find these changes early and fix the issues by retraining the model, auditing upstream systems or improving data quality. This helps with maintaining model accuracy and stability. SageMaker Model Monitor automatically detects issues in data and machine learning models and sends notifications when a specific threshold is exceeded.
There are four types of SageMaker monitoring jobs:
- Data Quality Monitoring Job
- Model Quality Monitoring Job
- Model Bias Monitoring Job
- Model Explainability Job
Data quality monitoring job checks for data types, completeness (missing values) of the current dataset, the number of columns, the number of unknown values and distribution distance between the current and baseline datasets. Data quality monitoring job runs a baseline job which analyzes input data and computes data schema constraints and statistics for each feature. The latter define a standard for detecting issues in data quality. Training data is commonly used as input for the baseline job. The outputs of the baseline job are automatically uploaded into an S3 bucket as constraints.json and statistics.json files. Constraint violations are stored as constraints_violations.json in the same S3 bucket.
Model quality monitoring job checks model performance by comparing the model predictions with the labels from the dataset created by SageMaker Ground Truth. Likewise, a baseline job calculates metrics and creates constraints to detect model quality drift. Model quality metrics are specific for each machine learning problem: regression, binary classification and multi-class classification. If any metric exceeds a suggested threshold the Model Monitor reports a violation.
Model bias monitoring and model explainability jobs rely on SageMaker Clarify for detecting drifts between distributions of real-life and training data, computing explainability (feature importance) metrics and generating model governance reports. Changes in data distribution and feature drift can happen due to anomalous events, temporary fluctuations or permanent changes in the real-world data. SageMaker Clarify calculates pre-training and post-training metrics to determine model bias. The impact of a specific feature on the model accuracy and changes in the feature ranking are tested using Shapley Additive exPlanations (SHAP) values.
We started with the data quality monitoring because having reliable data was a basic requirement for any work with machine learning models.
Data Capture
Model monitoring is the last step of the MLOps cycle. Let us assume that the model and its endpoint have already been deployed, and we need only to enable Data Capture feature and deploy job definition with a schedule. Data Capture logs are used as input data for the Model Monitor. Data Capture uploads the endpoint inputs and the inference outputs into S3 bucket. Model Monitor automatically parses the captured data and compares metrics with the baseline created for the model.
According to Amazon documentation, the model monitoring can be performed continuously with real-time endpoints or on-schedule for asynchronous batch transform jobs. To avoid confusion here, it should be noted that although SageMaker supports two types of endpoints, real-time and asynchronous, the Data Capture feature is available only for real-time endpoints. So asynchronous batch transform jobs use the data received from real-time endpoints, not asynchronous ones.
Data Capture is configured in the endpoint config:
endpoint_config = aws_sagemaker.CfnEndpointConfig(
scope=self,
id=’endpointConfig1’,
endpoint_config_name=’endpointConfig1’,
production_variants=[
aws_sagemaker.CfnEndpointConfig.ProductionVariantProperty(
initial_instance_count=1,
initial_variant_weight=1.0,
instance_type=’ml.m5.large’,,
model_name=’model1’,
variant_name=’variant1’
)
],
data_capture_config=aws_sagemaker.CfnEndpointConfig.DataCaptureConfigProperty(
capture_options=[
# For continuous monitoring, set the capture mode as ‘Input’.
# Both `Input` and `Output` modes are used for scheduled monitoring.
aws_sagemaker.CfnEndpointConfig.CaptureOptionProperty(
capture_mode="Input"
),
aws_sagemaker.CfnEndpointConfig.CaptureOptionProperty(
capture_mode="Output"
)
],
destination_s3_uri="s3://my-unique-bucket-name/data-capture",
enable_capture=True,
initial_sampling_percentage=100
capture_content_type_header=aws_sagemaker.CfnEndpointConfig.CaptureContentTypeHeaderProperty(
json_content_types=["text/csv"]
)
)
)
If the initial sampling percentage is 100, each time when an endpoint is invoked, a new JSONL file (a multi-line JSON-like string) is uploaded into S3 bucket. If several endpoint invocations happen almost simultaneously, several entries are added into the same JSONL file. The data is partitioned based on endpoint name, variant name, date and hour. The object key follows the pattern:
data-capture/endpoint-name/variant-name/year/month/day/hour/filename.jsonl.
Data Capture supports only CSV and flat JSON formats. When “text/csv” is used as a capture content header type, the output data is BASE64 encoded. An example of Data Capture logs for “text/csv” type :
{
"captureData": {
"endpointOutput:{
"observedContentType":"text/csv",
"mode":"OUTPUT",
"data":base64 encoded string,
"encoding":"BASE64"
},
"endpointInput:{
"observedContentType":"text/csv",
"mode":"INPUT",
"data": base64 encoded string,
"encoding":"BASE64"
}
},
"eventMetadata": {
"eventId":"ee9372b3-23f0-474c-a237-d704dd20000f",
"inferenceTime":"2023-02-07T05:58:52Z"
},
"eventVersion":"0"
}
When “application/json” is used as a header type, the output data (“data” key in the object above) is returned as a string-like JSON.
Data Pre-Processing
Model Monitor requires a specific structure of data object. The source data must be pre-processed if its structure, data type or encoding are not the same as expected. For example, input data for a data quality monitoring job must be in JSONL format. The JSON object must contain “captureData”, “eventMetadata” and “eventVersion” keys (similar to Data Capture logs), and the value of “data” key must be a UTF-8 encoded string. However, when the content type is “text/csv”, the value of the “data” key is a BASE64 encoded string, so the model monitoring job will fail without data pre-processing.
Here is an example of the pre–process script to decode source data and create a flattened JSON:
import base64
def preprocess_handler(inference_record, logger):
logger.info(f"Processing record: {inference_record}")
logger.debug(f"Debugging a processing record: {inference_record}")
input_data = inference_record.endpoint_input.data.rstrip("\n")
decoded_input_data = base64.b64decode(input_data).decode('UTF-8')
output_data = inference_record.endpoint_output.data.rstrip("\n")
decoded_output_data = base64.b64decode(output_data).decode('UTF-8')
outputs = decoded_output_data+','+decoded_input_data
return {str(i).zfill(20) : d for i, d in enumerate(outputs.split(","))}
Data post-processing is supported as well. The scripts for pre- and post-processing of data are stored in S3 bucket. Their location is defined by DataQualityAppSpecificationProperty of job definition construct.
data_quality_app_specification=aws_sagemaker.CfnDataQualityJobDefinition.DataQualityAppSpecificationProperty(
record_preprocessor_source_uri="s3://my-unique-bucket-name/scripts/data-quality/pre-process.py",
post_analytics_processor_source_uri="s3://my-unique-bucket-name/scripts/data-quality/post-process.py"
)
Docker Image for Model Monitor
Model Monitor runs in a Docker container that uses a custom or pre-built image. The latter one is stored in AWS ECR.
The pre-built images cannot be pulled directly, but we can use them when a monitoring job is submitted. The image can be accessed using ECR URI which depends on the region and a type of monitoring job. For example, for the data quality job in Sydney region, ECR URI is 563025443158.dkr.ecr.ap-southeast-2.amazonaws.com/sagemaker-model-monitor-analyzer.
data_quality_app_specification=aws_sagemaker.CfnDataQualityJobDefinition.DataQualityAppSpecificationProperty(
image_uri=f"563025443158.dkr.ecr.ap-southeast-2.amazonaws.com/sagemaker-model-monitor-analyzer",
container_arguments=[arg1, arg2],
environment=[{key1: value1}]
)
The Docker image for data quality monitoring is based on Apache Spark (version 3.3.0). It is built with Deequ (version 2.0.2) which is used to calculate baseline schema constraints and statistics. Deequ is designed to work with very large datasets and supports tabular data only, so Model Monitor processes only CSV and JSON data.
Inputs and Outputs of Data Quality Job
Model monitoring can be performed continuously or on a schedule (for batch transform). DataQualityJobInputProperty allows to choose one of these options.
For continuous monitoring:
data_quality_job_input=aws_sagemaker.CfnDataQualityJobDefinition.DataQualityJobInputProperty(
endpoint_input=aws_sagemaker.CfnDataQualityJobDefinition.EndpointInputProperty(
endpoint_name="endpoint1",
local_path="/opt/ml/processing/input/endpoint",
s3_data_distribution_type="FullyReplicated", # default value
s3_input_mode="File" # "Pipe" is for large datasets
)
)
For scheduled monitoring:
data_quality_job_input=aws_sagemaker.CfnDataQualityJobDefinition.DataQualityJobInputProperty(
batch_transform_input=aws_sagemaker.CfnDataQualityJobDefinition.EndpointInputProperty(
data_captured_destination_s3_uri="s3://my-unique-bucket-name/data-capture",
dataset_format=aws_sagemaker.CfnDataQualityJobDefinition.DatasetFormatProperty(
csv=aws_sagemaker.CfnDataQualityJobDefinition.CsvProperty( # JSON and Parquet are supported as well.
header=True
)
),
s3_data_distribution_type="FullyReplicated",
s3_input_mode="File"
)
)
The dataset format must be defined only for the batch transform input. The endpoint input does not have the dataset_format parameter. The monitoring job results are stored in S3 bucket defined by MonitoringOutputConfigProperty. Model artifacts can be
encrypted using a KMS key.
data_quality_job_output_config=aws_sagemaker.CfnDataQualityJobDefinition.MonitoringOutputConfigProperty(
monitoring_outputs=[
aws_sagemaker.CfnDataQualityJobDefinition.MonitoringOutputProperty(
s3_output=aws_sagemaker.CfnDataQualityJobDefinition.S3OutputProperty(
local_path='/opt/ml/processing/output',
s3_uri="s3://my-unique-bucket-name/outputs/data-quality/"
)
)
],
kms_key_id="str" # optional
)
Baseline Configuration
Baseline job calculates dataset statistics and constraints. They are used as a standard against which data issues are detected. When we define the monitoring job, we only need to indicate the baseline job name and location of constraints.json and statistics.json files.
data_quality_baseline_config=aws_sagemaker.CfnDataQualityJobDefinition.DataQualityBaselineConfigProperty(
baselining_job_name="data-quality-baseline-job",
constraints_resource=aws_sagemaker.CfnDataQualityJobDefinition.ConstraintsResourceProperty(
s3_uri="s3://my-unique-bucket-name/baseline/data-quality"
),
statistics_resource=aws_sagemaker.CfnDataQualityJobDefinition.StatisticsResourceProperty(
s3_uri="s3://my-unique-bucket-name/baseline/data-quality"
)
)
Network Configuration
SageMaker runs its jobs (processing, training, model hosting, batch transform, etc.) in containers. For security purposes, we limited access to the containers from the internet by creating a Virtual Private Cloud (VPC) with private subnets and directing all traffic to S3 buckets and CloudWatch over the VPC endpoints. When we specify IDs of security groups and private subnets in the network config of the job definition, SageMaker automatically creates Elastic Network Interfaces (ENIs) associated with security group (in at least one subnet) to connect job containers to resources in VPC. Remember, that when you decide to delete the VPC stack, you will need to disassociate these ENIs manually, because they are managed outside of the stack. To further improve security, all communications between distributed processing jobs can be encrypted at the expense of a potentially slowed down traffic/communications.
network_config=aws_sagemaker.CfnDataQualityJobDefinition.NetworkConfigProperty(
vpc_config=aws_sagemaker.CfnDataQualityJobDefinition.VpcConfigProperty(
security_group_ids=[security_group_id],
subnets=subnet_ids
),
enable_inter_container_traffic_encryption=True
)
Job Resources
SageMaker creates a cluster of instances to run a monitoring job. The parameters of this cluster are defined by ClusterConfigProperty. The volume attached to ML instances can be encrypted using a KMS key.
job_resources=aws_sagemaker.CfnDataQualityJobDefinition.MonitoringResourcesProperty(
cluster_config=aws_sagemaker.CfnDataQualityJobDefinition.ClusterConfigProperty(
instance_count=1,
instance_type='ml.m5.xlarge',
volume_size_in_gb=20,
volume_kms_key_id="str"
)
)
Finally, if we put all together, the data quality job definition will look like:
data_quality_job = aws_sagemaker.CfnDataQualityJobDefinition(
scope=self,
id="endpoint1-data-quality-job",
job_definition_name="endpoint1-data-quality-job-definition",
data_quality_app_specification=data_quality_app_specification,
data_quality_job_input=data_quality_job_input,
data_quality_job_output_config=data_quality_job_output_config,
data_quality_baseline_config=data_quality_baseline_config,
job_resources=job_resources,
network_config=network_config,
stopping_condition=aws_sagemaker.CfnDataQualityJobDefinition.StoppingConditionProperty(
max_runtime_in_seconds=900 # Maximum is 28 days
),
role_arn=role.role_arn # ARN of SageMaker execution role
)
SageMaker execution role has permissions to upload/download objects to/from respective S3 bucket, to use KMS key, to describe VPC resources and to create/delete network interfaces and their permissions.
Model Monitoring Schedule
When batch transform input is used, the monitoring job runs on a schedule, which we create as follows:
model_monitoring_schedule = aws_sagemaker.CfnMonitoringSchedule(
scope=self,
id="endpoint1-data-quality-monitoring",
endpoint_name="endpoint1",
monitoring_schedule_config=aws_sagemaker.CfnMonitoringSchedule.MonitoringScheduleConfigProperty(
monitoring_job_definition_name="endpoint1-data-quality-job-definition",
monitoring_type="DataQuality",
schedule_config=aws_sagemaker.CfnMonitoringSchedule.ScheduleConfigProperty(
schedule_expression="cron(0 * ? * * *)" # UTC
)
),
monitoring_schedule_name="endpoint1-data-quality-monitoring"
)
Known Issues with CDK
Recently, Roman Revyakin shared his experience working with CDK in this blog post. CDK issues are described in details with a great sense of humor and I certainly recommend reading it. All the problems described in the post were encountered as we worked on this project.
Conclusion
Machine learning systems are quite complex and could be hard to develop, train, test, deploy and support. SageMaker Model Monitor is a great tool for maintaining the accuracy and stability of machine learning models. We found that it was relatively easy to configure and deploy. We hope that our customers will also be satisfied with its performance.
For more information
Model Monitor using Python SDK