Service Workbench Scaling - Part I

Table of Contents
AWS Service Workbench was developed to provide customers with simple and fast access to cloud computing resources. Service Workbench is especially attractive for researchers, as they do not need to be experts in ‘cloud’ technology and AWS infrastructure to use it. Researchers can securely store and share their data, and there is no need for them to wait for their turn to use university computing facilities.
However, a DevOps team is still required to add custom features, support users and improve their experience. With this aim, Kablamo was contracted by a university in NSW and within a few months, a customized Service Workbench product was released into production. The custom features added to the base Service Workbench configuration are described in our blog here. Soon after the release, 14 research groups were onboarded, and we faced a scaling problem.
In Part I, I explain how a single S3 bucket policy became a bottleneck, and I outline possible ways to overcome these limitations and the solution we have chosen. Part II will then describe how we automated the creation of personal user roles to overcome IAM limits at scale.
S3 bucket policy limit
Service Workbench supports a multi-account architecture. The resources required for Service Workbench’s frontend and backend are deployed in a ‘main’ account, while the computing resources such as EC2 instances, SageMaker Notebook instances and EMR clusters are deployed in ‘hosting’ accounts. A single S3 bucket in the main account stores study data for all users.
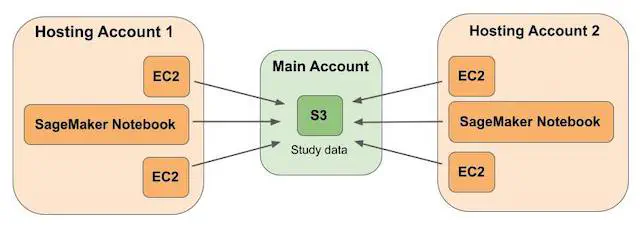
Uploading study data from instances requires cross-account access, so the policy on the study data bucket must have corresponding permissions. Each study has its own prefix in the study data bucket. When users create a new workspace, they can choose multiple studies, and the corresponding prefixes will be mounted on the instance using goofys. Service Workbench offers two types of ‘studies’ that can be stored in the study data bucket:
- MyStudy - The user has a personal prefix, and the data under the prefix is not shared with anyone else.
- Organization - The prefix is shared between multiple users. Users can be given read-only or read-write access to the data. Access to Organization studies is provided by study administrators (the user who creates the study).
For security purposes, the Service Workbench UI does not allow users to see personal studies of other users. The access to the required prefixes is controlled by an instance IAM role and the policy of the study data bucket. Each study has its own statement in each policy. Note that the study data bucket is created in the main account, while the computing resources and their roles are deployed in the hosting accounts. To allow cross-account access, the bucket policy is updated for each instance. The permissions are removed from the bucket policy only when the instance is terminated. It is easy to see that when many users launch instances with multiple studies, and keep them in the running or stopped state for prolonged time, the bucket policy limit (20 KB) is hit pretty fast. Moreover, the users lose access to their data as soon as the instance is terminated (many of our users complained about this). Also, some users required the ability to upload or download large objects which would otherwise time out through the Service Workbench UI.
Therefore, we started searching for a solution to solve all of these problems in one go.
Possible Solutions
The possible solutions included the use of a Service Workbench feature called Data Sources; the creation of IAM users with required permissions; or the use of IAM roles. Let us consider them one by one.
1. Data Sources
Data Sources is a Service Workbench feature that allows users to use their own buckets in hosting accounts. Although it solves the problem with the overcrowded bucket policy of the study data bucket, it requires additional effort from a DevOps team member. The team member has to register each study that uses a custom bucket, indicate all required information (account ID, bucket name, prefix, KMS key ID if it was used for bucket encryption, etc.) and create a new stack in the hosting account with an IAM role for bucket access. As non-admin users have to wait for the registration of their studies and it puts more workload on the administrator’s shoulders, our customers decided not to use Data Sources.
2. IAM Users
The permissions added to the study data bucket policy are duplicated in the instance IAM roles, so the bucket policy could be significantly simplified. The hosting accounts are used only for the deployment of the computing resources for specific research groups, and the university has full control over them. If we could find a way to disable bucket policy updates (see below), IAM users could be used to provide Service Workbench users with permanent, cross-account access to their studies.
This solution was not suitable for us because our customer uses Okta for identity federation. Okta’s integration with AWS allows end users to authenticate to one or more AWS accounts and gain access to specific roles using single sign-on with SAML. Therefore, our choice fell on IAM roles.
3. IAM Roles
As a part of our Service Workbench customisation,
we had already created a user role and two Lambda functions, launch-hook and terminate-hook. The user role was assumed by all users and it
had multiple inline policies with permissions allowing the users to access their prefixes in the study data bucket (one policy per
instance). The Lambda functions were triggered by the RunInstances and TerminateInstances API calls. The launch-hook function added a new
inline policy, while the terminate-hook function deleted the policy once the instance was terminated (the deletion of the inline
policies was required due to the 10 KB limit for inline policies - total, not per policy).
We could use managed policies, but it would not solve the problem either, because the managed policy has its own limits. They include 6144 characters per policy and a soft limit of 10 managed policies per role (with a hard limit of 20). The number of the users interested in Service Workbench continued to grow, and it was clear that we were going to reach IAM policy limits very soon. Therefore, we decided to create personal IAM roles for each user.
Personal User Roles
The default limit for the number of IAM roles per account is 1000, with a hard limit of 5000. As a rule, research groups are much smaller than this, and they can be easily split into smaller sub-groups with their own accounts - so we did not need to worry about these limits. To create and securely use personal user roles, we had to answer the following questions:
- How much can we simplify the study data bucket policy?
- Can we disable bucket policy updates?
- What happens when a new hosting account is onboarded?
- How can we automate the creation of personal user roles?
- The study data bucket is encrypted using a KMS key: should we update the KMS key policy, or create KMS grants?
- How can users securely assume their personal user role?
We’ll tackle three of these questions now, and the final three questions will be discussed in Part II of this blog post.
1. Simplifying the study data bucket policy
The study data bucket policy has two parts: static and dynamic. The static part remains unchanged at all times.
It denies:
- requests not using SigV4,
- requests not using TLS/HTTPS,
- and object uploads not using default encryption settings.
We decided to leave the static part of the bucket policy unchanged.
The dynamic part of the policy however contains statements which are added for each instance at launch time, before being removed at instance termination. We disabled bucket policy updates (see below) and replaced the dynamic part of the bucket policy with the following statement:
{
"Sid": "CrossAccountAccess",
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::hosting-account-1-id:root",
"arn:aws:iam::hosting-account-2-id:root",
"arn:aws:iam::hosting-account-3-id:root"
]
},
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::study-data-bucket-name",
"arn:aws:s3:::study-data-bucket-name/*"
]
}
This policy allows cross-account access from all hosting accounts onboarded to Service Workbench. Access to the hosting account is controlled using Okta. Instance IAM roles limit access to specific prefixes, and do not allow the users to access the studies which are not shared with them or that belong to other users.
In other words, we decided that we could trust the hosting accounts to control access to the study data bucket, rather than needing to control access at both the bucket and hosting account level.
2. Disable study data bucket policy updates
To disable Service Workbench’s updating of the study data bucket policy so that our own dynamic changes would not be overwritten,
we had to fork service-workbench-on-aws, add the required changes, and
reinstall Service Workbench. In our case, Service Workbench was being installed as
part of a CodePipeline pipeline. We used a custom CloudFormation template (installer.yaml), a shell script (swb-install.sh),
and a custom AMI
built with HashiCorp Packer. The template deployed an EC2 instance, IAM role, VPC, security group
and other resources required to create an instance to run Service Workbench installation. The shell script installed
Node.js and pnpm, prepared Service Workbench configuration files (dev.yaml or prod.yaml, depending on the environment),
and ran scripts/environment-deploy.sh
from the service-workbench-on-aws repository.
So in order to disable study data bucket policy updates, we needed to:
-
Fork the
service-workbench-on-awsrepository -
Create a new branch
-
Comment out lines 104 and 159 in environment-resource-service.js:
104: await this.addToBucketPolicy(requestContext, studiesToAdd, memberAccountId); ... 159: await this.removeFromBucketPolicy(requestContext, studiesToRemove, memberAccountId); -
Commit and push the changes
-
Tag the branch
git tag -a tag-name commit-id -m tag-name git push origin - -tags -
Change the installation URL to https://github.com/my-project/service-workbench-on-aws-fork/archive/refs/tags/tag-name.tar.gz
-
Trigger a re-installation of Service Workbench
3. Onboarding a new hosting account
When we initially faced the scaling problem, we had 14 hosting accounts. Their IDs were added to the CrossAccountAccess statement of the
bucket policy manually. To automate updating this statement when a new hosting account is unboarded, we created the
update-bucket-policy Lambda function,
enabled DynamoDB Streams
on Service Workbench’s AwsAccounts table, and added an Event Source Mapping
to integrate them. The Event Source Mapping reads events from the DynamoDB stream and invokes the Lambda function with the changed data.

DynamoDB Streams captures a time-ordered sequence of item modifications in the DynamoDB table and stores this information in a
log for up to 24 hours. Each modification corresponds to exactly one record within the stream. The records are written near-real-time.
They contain a sequence number, event name, stream view type, stream ARN and item ‘image’ (an example of the event payload can
be found here).
The event names include INSERT, MODIFY and REMOVE - corresponding to creation, updating and deletion of an item,
respectively.
The stream view type allows one to choose what information to receive with the event payload. The stream view types include:
NEW_IMAGE- the item image after the modificationOLD_IMAGE- the item image before the modificationNEW_AND_OLD_IMAGES- both old and new item imagesKEYS_ONLY- primary keys of the modified record
If an item is deleted from a table, its ’new image’ is empty. So to get the ID of the deleted account, we have to use the ‘old image’.
Therefore, NEW_AND_OLD_IMAGES was chosen as the desired stream view type.
To enable DynamoDB Streams and create an Event Source Mapping, we used another Lambda function, post-install-hook. This
function had already been created as part of our customisations for Service Workbench. It runs only once, immediately after Service Workbench
installation. The service role attached to the post-install-hook function requires the following permissions:
- Effect: Allow
Action:
- dynamodb:ListStreams
- lambda:ListEventSourceMappings
Resource: '*'
- Effect: Allow
Action: dynamodb:UpdateTable
Resource: !Sub arn:aws:dynamodb:${AWS::Region}:${AWS::AccountId}:table/${AwsAccountsTableName}
- Effect: Allow
Action: lambda:CreateEventSourceMapping
Resource: '*'
Condition:
ArnLike:
lambda:FunctionArn: !Sub arn:aws:lambda:${AWS::Region}:${AWS::AccountId}:function:${UpdateBucketPolicyFunctionName}
The Python code to enable DynamoDB Streams on the Users table reads:
import boto3
dynamodb_streams = boto3.client(‘dynamodbstreams’)
aws_accounts_table_name = os.environ['DYNAMODB_AWS_ACCOUNTS_TABLE_NAME']
response = dynamodb_streams.list_streams(TableName=aws_accounts_table_name)
if len(response['Streams']) > 0:
aws_accounts_stream_arn = response['Streams'][0]['StreamArn']
else:
response = dynamodb.update_table(
TableName=aws_accounts_table_name,
StreamSpecification={
'StreamEnabled': True,
'StreamViewType': 'NEW_AND_OLD_IMAGES'
}
)
aws_accounts_stream_arn = response['TableDescription']['LatestStreamArn']
In the same function, the creation of the Event Source Mapping:
lambda_client = boto3.client(‘lambda’)
update_bucket_policy_function_name = os.environ['UPDATE_BUCKET_POLICY_FUNCTION_NAME']
response = lambda_client.list_event_source_mappings(
EventSourceArn=aws_accounts_stream_arn,
FunctionName=update_bucket_policy_function_name
)
if len(response['EventSourceMappings']) == 0:
response = lambda_client.create_event_source_mapping(
EventSourceArn=aws_accounts_stream_arn,
FunctionName=update_bucket_policy_function_name,
Enabled=True,
StartingPosition='LATEST',
BatchSize=1
)
And finally, the IAM role for the update-bucket-policy function must include the following permissions:
- Effect: Allow
Action: dynamodb:ListStreams
Resource: "*"
- Effect: Allow
Action:
- dynamodb:DescribeStream
- dynamodb:GetRecords
- dynamodb:GetShardIterator
Resource: !Sub arn:aws:dynamodb:${AWS::Region}:${AWS::AccountId}:table/${Environment}-${RegionShortName}-${NamePrefix}-AwsAccounts/stream/*
- Effect: Allow
Action:
- s3:PutBucketPolicy
- s3:GetBucketPolicy
Resource: !Sub arn:aws:s3:::${AWS::AccountId}-${Environment}-${RegionShortName}-${NamePrefix}-studydata
Note that in the above function code and IAM policies, a number of parameters and environment variables were set to provide the specific naming used in the deployed environment.
When a new account is added (event name INSERT) to the AwsAccounts table, its ARN is added to the Principal array in the CrossAccountAccess
statement of the bucket policy. When an account is deleted from the table (event name REMOVE), its ARN is subsequently removed from the
list of principals. The update-bucket-policy function takes the following steps:
- If the event name is
MODIFY, return early - If the event name is
INSERT, get the account ID from the ’new’ image - If the event name is
REMOVE, get the account ID from the ‘old’ image - Get the current study data bucket policy
- Check if the statement with
SidCrossAccountAccessalready exists a. If the statement exists, update itsPrincipalarray i. If the event name isINSERTand the account ARN is not in the list of principals, append it ii. If the event name isREMOVEand the account ARN is in the list of principals, remove it b. Else create the statement with all of the necessary principals listed - Put (save) the updated bucket policy
What’s next?
The next steps in our chosen solution include the creation of personal user roles and KMS grants, as well as policies allowing users to start a Session Manager session and access the study data and egress store buckets. Part II of this post is coming soon!
For more information on Service Workbench, see: