Seven features we added to a basic configuration of Service Workbench

Table of Contents
In this blog, I describe seven features Tim Malone and I added to a basic configuration of AWS Service Workbench to improve its observability and security and make life easier for administrators, researchers and students.
What is AWS Service Workbench and what can it be used for?
Many research areas require computational power to perform complex modeling and data analysis. Genome sequencing, financial modeling, chemical pathway simulation, flow dynamics modeling and bushfire predictions are just a few of them to name. Until recently, universities had to maintain their own computing infrastructure that required a large investment in hardware, as well as high maintenance and development costs. Upgrading and scaling the existing infrastructure introduced additional challenges. Also, most academic workloads are uneven resulting in high peak loads with low availability of resources and, conversely, periods of time when the infrastructure was largely unused. Due to these reasons, cloud computing technology has gained a large following over recent years. More and more universities are considering migration to ‘cloud’ or have already started it.
Cloud computing technology provides on demand network access to a shared pool of configurable computing resources such as storage, databases, network infrastructure, software, artificial intelligence and machine learning. The resources are provided quickly and automatically, without having to order infrastructure and wait for delivery. They can be accessed via different platforms, on-premise devices, laptops and mobile devices. The benefits of cloud computing include high scalability and reliability, a decrease in operational and maintenance costs, service flexibility, service variety and a pay-for-what-you-use payment model. All this makes ‘cloud’ especially attractive for online education and research.
However, the use of cloud computing resources require additional training or IT support and not many researchers and students have time, motivation or funding for this especially when they come from areas far from IT or computer science. To solve this problem, AWS has released Service Workbench, an open source (Apache License Version 2.0) secure solution, allowing the user to create pre-configured, administrator-approved computing resources using a few clicks in a user interface (UI). Students and researchers do not need to be experts in ‘cloud’ technology and AWS infrastructure. They simply choose one of the pre-approved configurations in the UI and click the ‘Create New Workspace’ button to launch an Amazon EC2 instance, SageMaker notebook instance or EMR cluster. Moreover, the researchers and students can create and share Research Studies. Their data is securely stored in an encrypted Amazon S3 bucket with high durability and virtually unlimited capacity.
Service Workbench Infrastructure
To understand why we decided to add custom features to the base configuration, let us briefly describe Service Workbench’s infrastructure. The installation instructions and user guide documentation can be found in the GitHub repository awslabs/service-workbench-on-aws, so we will not go in much detail regarding them here.
AWS Service Workbench supports multiple accounts. The resources for the web frontend and backend are deployed into a Main Account using a CloudFormation template (Figure 1). The web frontend is hosted in an Amazon S3 bucket and made available through Amazon CloudFront with Lambda@Edge. The web frontend authentication is performed using Amazon Cognito, supporting federated identity providers such as Google, Facebook, Okta, etc. The backend utilizes Amazon API Gateway to invoke an AWS Lambda function which triggers AWS Step Functions workflows. This infrastructure interacts with AWS Service Catalog and Amazon DynamoDB tables
- to manage the content, users, environments, workflows and AWS accounts in AWS Organizations;
- to access data in S3;
- and to instantiate out-of-the-box compute instances for Amazon EMR, Amazon SageMaker and Amazon EC2 with Windows and Linux operatings.
AWS Service Catalog stores CloudFormation templates of the computing resources. Each computing resource has its own Product ID and can have multiple product versions. The configuration files of the computing resources are stored in S3. DynamoDB tables store all required information about users, accounts, environments, workflows, etc. Several S3 buckets are created during Service Workbench installation. They store logs, study data, bootstrap scripts, templates of Service Catalog products, artifacts and configurations. All buckets are encrypted.
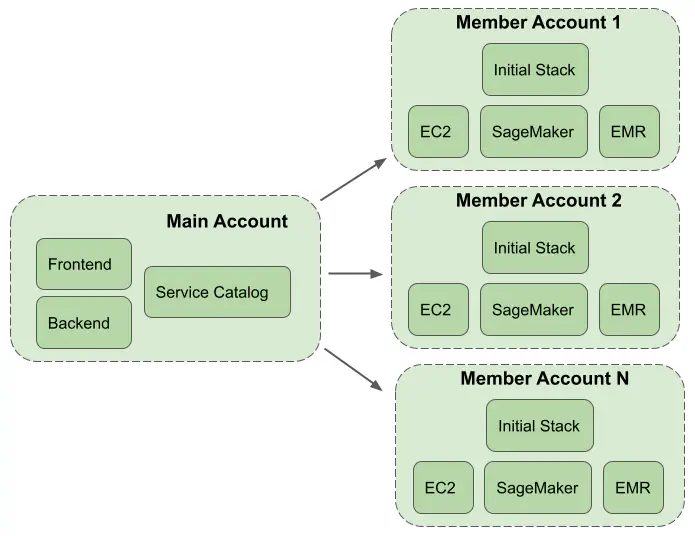
Figure 1. Multi-account structure of AWS Service Workbench.
The computing resources can be deployed into multiple Member Accounts (Figure 1), also known as hosting accounts. The Member Accounts are added using a few clicks in the Service Workbench UI (see Post Deployment Guide). When a new account is added an initial CloudFormation stack, containing an Amazon VPC and cross-account IAM roles, is created within the account. The computing resources are placed into the VPC and access to them is controlled by security groups, a network ACL and IAM roles. By default, the connection to an EC2 instance is performed through the standard SSH port. SSH is a powerful security tool, but it has several drawbacks. When an SSH connection is used in Service Workbench, starting sessions and copying files via the CLI requires repeat authorization for each request (due to the use of EC2 Instance Connect). Downloading files via the AWS S3 console is not supported out of the box. Also, if the instance is compromised and security groups aren’t effectively locked down, an attacker can access the instance and exfiltrate any data stored on it. This brings us to the first custom feature we added - an SSH connection tunneled over a Session Manager session.
Custom features added to the base configuration
1. SSH connection tunneled over Session Manager session
In our modified solution, in order to open an SSH connection, the user first has to start a Session Manager session. The session is an encrypted connection between the user and an EC2 instance. Session Manager uses AWS IAM to authenticate the user and determine which resources they are authorized to access. After the user is authenticated, Session Manager sends a message to the Systems Manager (SSM) Agent to open a two-way communication channel between the user and the EC2 instance. The channel is used by SSH as a tunnel to connect to the EC2 instance. As the user is already authenticated by Session Manager, the SSH daemon on the instance does not require any further authentication. So, we configured the SSH daemon with both PasswordAuthentication and PermitEmptyPasswords parameters set to yes, and set the local ec2-user’s password to an empty string.
To protect the SSH daemon against unauthorized access, we configured it to listen only on 127.0.0.1, so that any requests originating from outside of the instance are rejected. Session Manager works via the locally installed Amazon SSM Agent. Moreover, all instances launched through Service Workbench by default have a security group rule that opens port 22 only to the user’s current IP address. In the case if a user happens to modify both the SSH Daemon config and the security group rule, we added a NACL rule to the subnet in which the instance runs to reject all inbound traffic on ports 22, 80 and 443. Service Workbench allows a user to authorize access to these three ports only.
Due to the above changes, when an SSH connection is tunneled over a Service Manager session, the user does not need to create SSH keys. Therefore, we added a JavaScript file that hides the SSH-related parts of the Service Workbench UI from any non-administrator user.
2. Budget alarms
Although Service Workbench is generally free of charge (other than minor S3, Lambda and API Gateway charges), users have to pay for the computing resources such as EC2 instances, SageMaker notebook instances or EMR clusters. These expenses can grow quite fast especially when large instances or EMR clusters are used by many users. As the budget is limited, it is useful to get notified when the budget limit is reached and to know how much each user spends on which project. Service Workbench UI has a Dashboard showing the information about the costs per index per user and total costs for the last 30 days. ‘Indexes’ and ‘projects’ form a hierarchy thtough which Service Workbench utilizes the Member Accounts. Each account can have multiple indexes and each index can have multiple projects. The users can be added to different projects, and the costs they incur are transparent. However, at the moment of writing, Service Workbench does not have any built-in budget alarms. So we used AWS Budgets to monitor AWS billing data and send alerts to an SNS topic and emails of individual users when a specific budget limit is reached in a 30 day period.
3. EC2 alarms
We added Amazon CloudWatch alarms to monitor EC2 instance performance. The alarms send alerts to an SNS topic and email when CPU utilization is higher than 95% for 3 minutes or lower than 5% for an hour. Memory and disk space utilization are also monitored. The alerts are sent when the memory utilization is higher than 85% for 3 minutes or the percentage of used disk space is higher than 80% for 3 minutes.
4. Microsoft Teams and Slack notifications
Microsoft Teams and Slack notifications are added with the aim to further improve Service Workbench observability. We created a new CloudFormation stack containing a Lambda function, its IAM role, an SNS topic and EventBridge rules (Figure 2). The Lambda function is triggered when the SNS topic receives one of the following alerts:
- a new Workspace is launched
- a Workspace is terminated
- Workspace termination has failed
- a new configuration file is uploaded to S3 bucket
- specified limits on CPU, memory and disk utilization for EC2 instance are exceeded or EC2 instance is idle for an hour (low CPU utilization)
- specified budget limit is exceeded
The alerts are forwarded by the Lambda function to Microsoft Teams and Slack webhooks. The webhook URLs are stored in AWS Secrets Manager. Besides the ‘global’ alerts topic, each user has a personal SNS topic. This topic is created and configured upon the first workspace launch (by a launch-hook lambda created by us for custom modifications) and, along with the same subscriptions as the ‘global’ topic, automatically has the user’s email address subscribed to it.
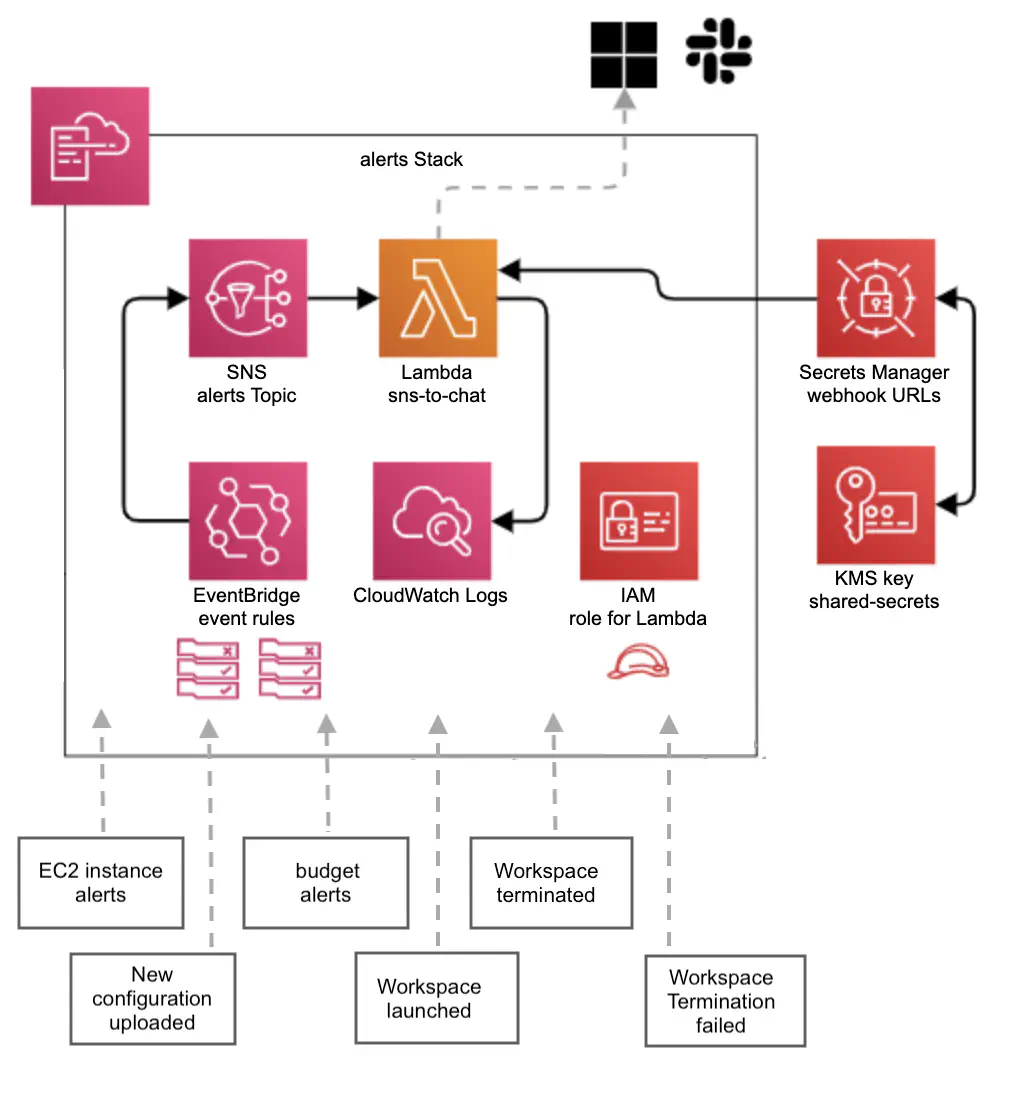
Figure 2. A schema of an alerts stack and the types of alerts received by an SNS topic.
5. Logging
Service Workbench uses CloudWatch Logs to store technical logs from Lambda functions, API Gateway, and CodeBuild jobs. API Gateway logs tend to hold detailed access logs for API endpoints deployed by Service Workbench. This includes:
- Log entries containing a value for authorizer.principalId. In some cases, identity.sourceIp can be used to track specific actions undertaken by a user in the Service Workbench UI;
- Log entries where the httpMethod is POST, PUT, or DELETE generally refer to actions a user has taken; methods of GET generally refer to read requests.
Access logs from CloudFront and access logs from some S3 buckets (study data and egress store, for example) are stored in a dedicated logging bucket with a name following the pattern AccountId-Environment-ShortRegionName-NamePrefix-logging. The bucket is created automatically during Service Workbench installation. To make processing of the access logs easier, we added a new stack (Figure 3) containing Amazon Athena workgroup with named queries covering logs of CloudFront, egress store, study data S3 buckets, and API Gateway. The output of each query is stored in the logging bucket under the athena prefix. As Amazone Athena works in tandem with AWS Glue, the logging stack also creates a Glue database and three tables with schemas for the aforementioned log types.
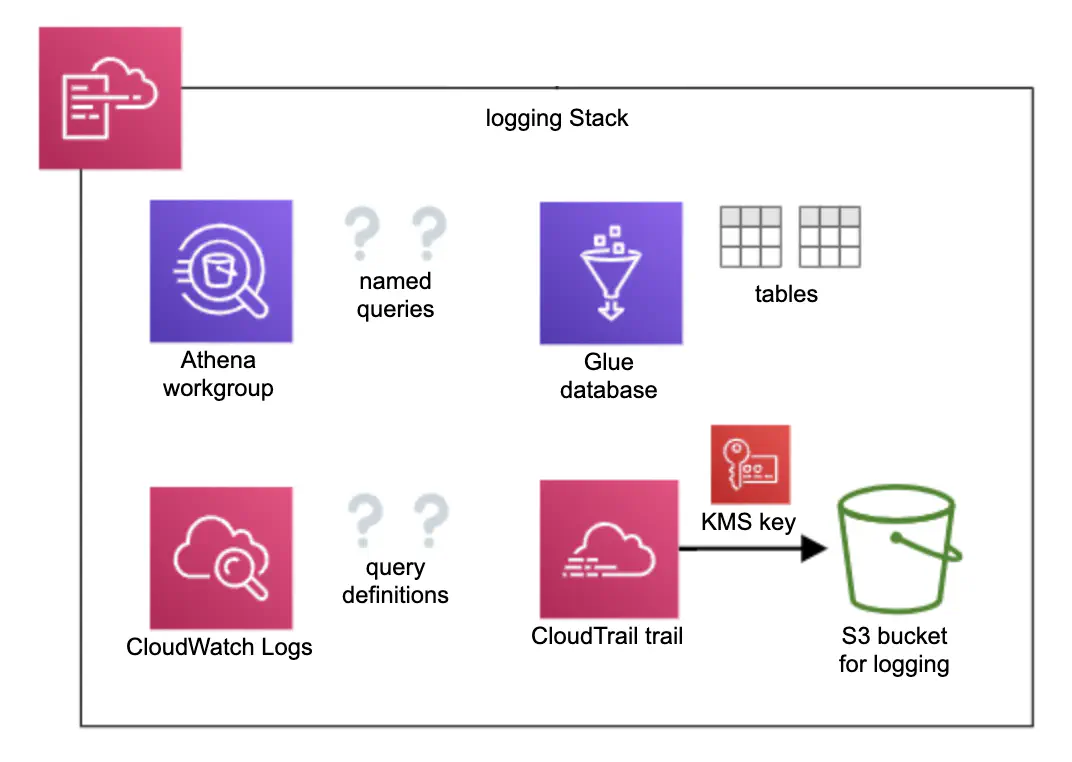
Figure 3. A schema of the logging stack which contains resources for effective log processing and CloudTrail trail with a separate logging bucket.
To improve visibility of actions taken in AWS accounts, we added AWS CloudTrail trail with a separate encrypted S3 bucket. CloudTrail stores a record of every request made to the AWS API within the account, with the exception of data-level requests for services like S3 and DynamoDB. This allows us to identify who or what took which action, what resources were acted upon, when the event occurred, etc.
6. Codified workspace configuration
CloudFormation templates of computing resources as well as all template versions are stored in in S3 bucket named AccountId-Environment-ShortRegionName-NamePrefix-artifacts under service-catalog-products prefix as well as in AWS Service Catalog. They are referenced in the Workspace Type section of Service Workbench UI, as AWS Service Catalog Products (Figure 4). For example, in the case of EC2 Windows-v1, ‘EC2 Windows’ and ‘v1’ are the names of the product and its version, respectively. Their IDs are random alphanumeric strings created in Service Catalog and used in DynamoDB tables.
The Catalog Product Version must be imported (the ‘Import’ buttons in Figure 4) and approved by an administrator before it can be used as a Workspace Type to launch the required computing resource. Each Workspace Type can have several configurations which are created by choosing multiple parameters including ID of an Amazon Machine Image (AMI) (for launching EC2 instance), asw well as instance types, allowed roles, tags, etc. The access to specific configurations is controlled by the user roles. At the time of writing, there are only four roles:
- admin
- researcher
- guest
- internal-guest
When a user creates a new Research Workspace to launch a computing resource, they choose one of the available configurations. Creating workspace type configurations can easily become a tedious task especially when there are many of them and multiple tags are used, so we decided to codify these configurations.
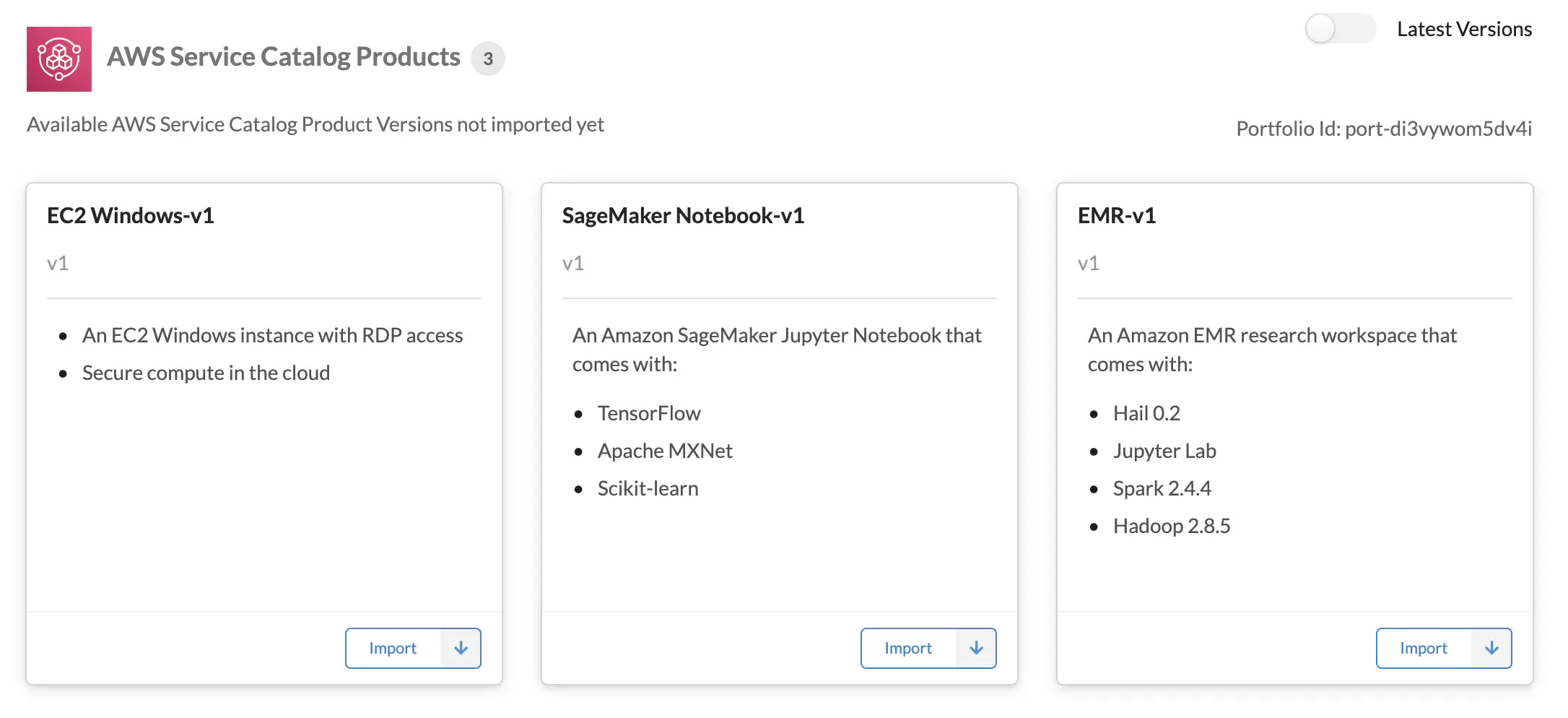
Figure 4. The latest versions of CloudFormation templates of the computing resources stored in Service Catalog are represented as AWS Service Catalog Products in the Workspace Types section of Service Workbench UI. To switch to All Versions, toggle the Latest Versions switch in the top right corner.
Workspace type configurations are stored as JSON like files under configs prefix in S3 bucket AccountId-Environment-ShortRegionName-NamePrefix-env-type-configs. The bucket is created automatically during Service Workbench installation. The name of the configuration file follows the pattern product ID-product version ID. To modify the configuration files and upload them into the corresponding S3 bucket, we added a new CloudFormation stack which creates a CodePipeline pipeline (Figure 5).
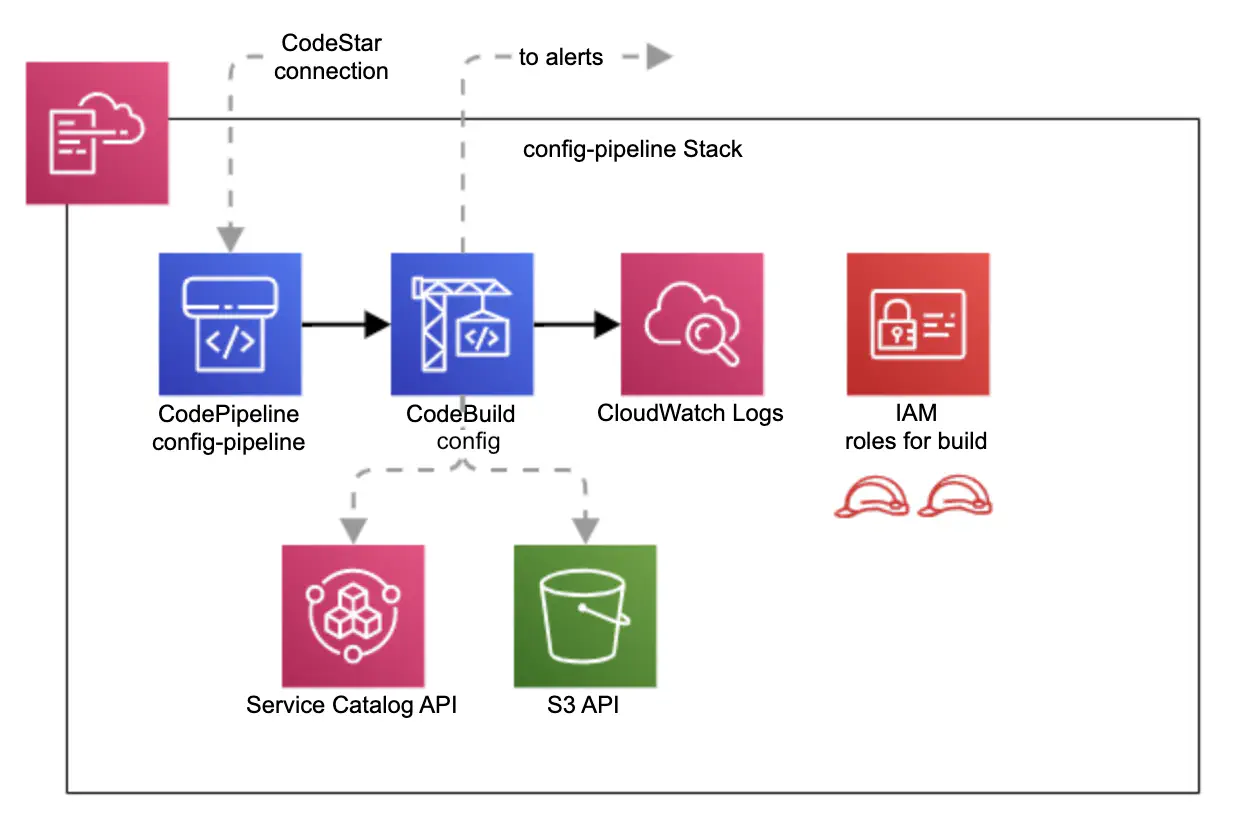
Figure 5. A schema of the stack creating a CodePipeline pipeline for updating workspace type configuration files and uploading them into S3 bucket.
The config pipeline is executed on each push into a working GitHub repository. The CodeBuild project then runs a script which
- gets the product ID and product version ID from Service Catalog, using the names of the product and required version
- generates the name of the config file using the product ID and product version ID
- generates the new configuration by retrieving the appropriate AMI ID and merging default tags with the configuration in the repository
- compares the new config file with the existing config file stored in the S3 bucket
- uploads the new version of the config file into the S3 bucket if any differences are detected
- sends notifications to Microsoft Teams and Slack for successful or failed uploads
CodeBuild logs are stored in CloudWatch Logs. Access to Service Catalog and S3 bucket is controlled by a corresponding IAM role.
7. Building and testing of multiple AMI images
An AMI image provides information required to launch an EC2 instance. It can include installation of various packages and plugins. For example, R packages for genomic analysis or nonlinear optimization, agents such as the CloudWatch or Systems Manager agent, etc. Installation of some packages is not trivial, so including them into an AMI image makes life easier for students and researchers. As different research groups require different packages, it is useful to have multiple AMIs with specific sets of packages and plugins.
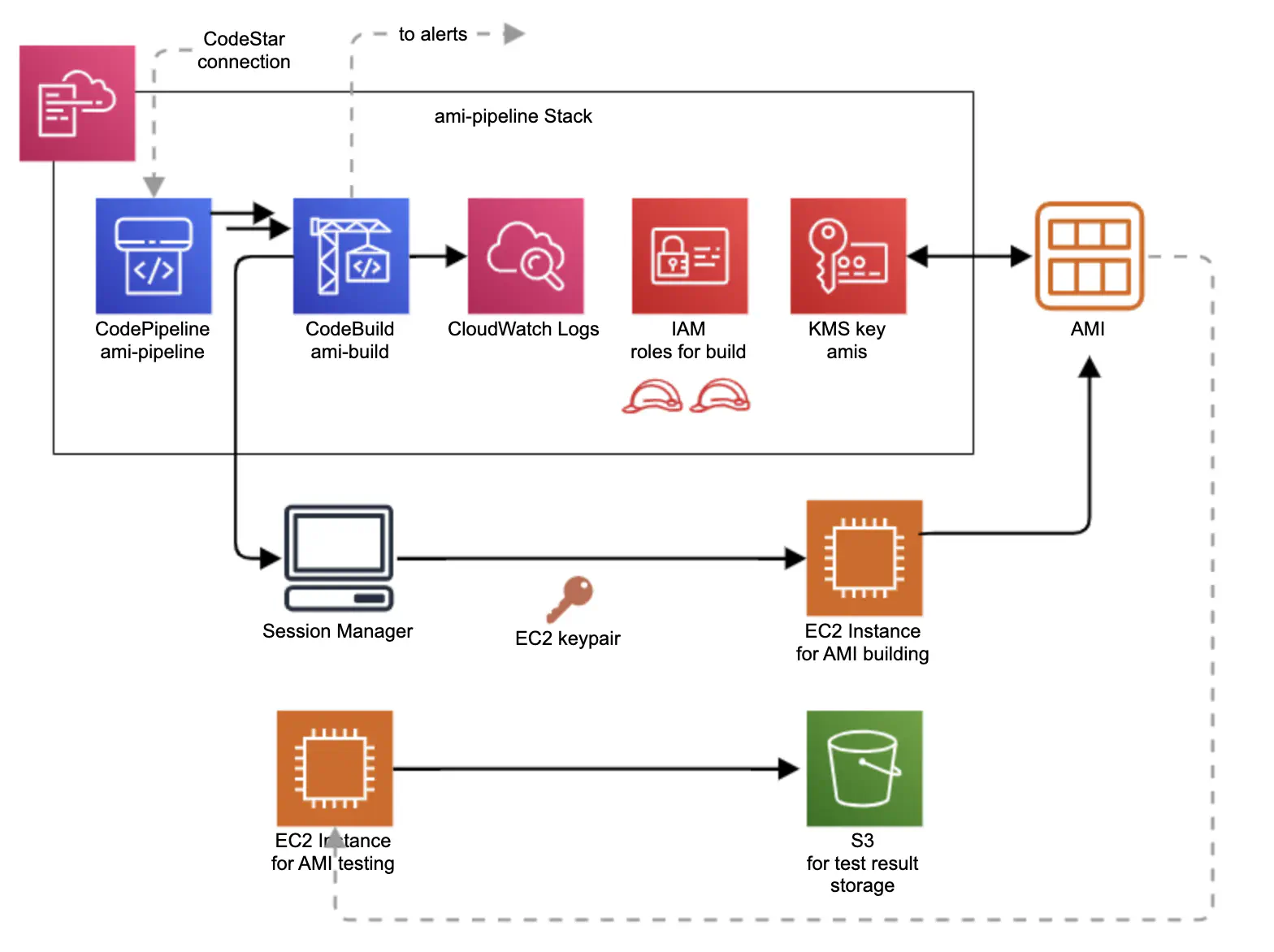
Figure 6. A schema of the stack creating a CodePipeline pipeline for building multiple AMI images for EC2 instances.
We created a CodePipeline pipeline for building, testing and auto-deploying AMIs (Figure 6). HashiCorp Packer was used to control the building of each individual AMI. Packer’s behavior is determined by the Packer template, which consists of a series of declarations and commands for Packer to follow. This template tells Packer what plugins (builders, provisioners, post-processors) to use, how to configure each of those plugins, and what order to run them in. A new folder amis was added to our existing GitHub repository. Each AMI has its own subfolder inside the amis folder with a corresponding Packer template, a test script to test the AMI, and other related scripts such as a script to install required R packages or a script to check Session Manager permissions. The CodeBuild project runs a script which
- checks amis folder for buildable changes and quits if no changes are found
- installs Packer, and the Session Manager plugin
- starts Docker daemon
- checks Shell scripts and Packer template for errors
- builds any Packer templates that can be found in subfolders under amis
- tests each new AMI, by booting up a new instance with a test script and waiting for it to return a result via an S3 object
- triggers the config pipeline for auto-deployment of new AMIs
- sends notifications about errors, or on a successful build
CodeBuild logs are stored in CloudWatch Logs. Each AMI is KMS
encrypted and has permissions which allow sharing the AMI with all users inside the AWS Organization. The CodeBuild project uses a
Session Manager session to connect to an EC2 instance which is used to build and test each AMI. The instance is automatically
terminated if the building and testing are successful. The results of AMI testing are stored in an S3 bucket.
A few words in conclusion
Service Workbench is still a very new AWS solution. The Kablamo team was lucky enough to perform one of the first ‘test-drives’ in Australia, and to see it in action. The project was commissioned by one of the largest NSW universities. Service Workbench was very well received by researchers. After Service Workbench had been deployed to production, more than ten research groups quickly requested access to it.
For more information on Service Workbench, see: