ABC CoDA, designing and building a digital archive to last a decade
Table of Contents
The ABC Archive known as CoDA is one of the earliest large projects Kablamo has built. While we do have an ABC Archive case study about it, I thought it would be nice to get an engineering perspective on it.
The Brief
The brief from the ABC at the time was fairly simple. They had many disparate systems which held records from the the founding of the ABC (over 80 years worth of content), and want to combine them into one system. The new system was to be self service to ABC staff, reduce the content retrieval time from 2 weeks to minutes, grow with the ABC’s needs, consume all existing systems content over time and be production ready in 6 months.
It should also be mentioned, a lot of the systems that would be replaced had been running for a long time, decades in some cases and having a similar system lifespan should be considered, although this was not a strict requirement.
Looking back, I can see we nailed every one of the requirements. To date, the ABC has ingested content from over a dozen systems, CoDA is available internally to all ABC staff, if given the right access it allows you to access the content for any media purpose, and has grown to over 6 TB of audio, video and image content. The system itself has stood the test of time, with continued development over the last 7 years, including new functionality being added, new system integrations and its hook into the critical workflows of the ABC.
How we did it
One of the other requirements at the ABC at the time was to leverage Amazon Web Services (AWS), with the the idea to offload infrastructure management to managed services, but only where it was considered appropriate.
One of the first decisions came early. All content would be stored using S3, with the intention to transition all master records into glacier over time. A fairly simple decision given that we expected the system to grow to well in excess of a petabyte of content once the initial imports were made. However somewhat controversially at the time we also decided to put all the metadata describing the records in S3 as well.
I say controversially because there was and still is a push from AWS to put JSON records, which the metadata was going to be into DynamoDB. DynamoDB is a fine system, however we made the case that when it came to paging and scanning multiple records DynamoDB can quickly become expensive, and that if we built with it in mind being able to move out of AWS should that decision come up would require a rebuild of the data access.
What also helped was the choice to use ElasticSearch for both search functionality, and as a cache. ElasticSearch in a few key ways, such as a key/value store, can work like DynamoDB while also providing the rich search experience that ABC users were telling us they would need, which was the primary reason for the push to use it.
I recall having to show users how it could be better than the previous systems they were using which had some non-SQL flavour query syntax (FQM from memory), and my go-to demonstration was a search of
sydney~1 -sydneyagainst the record titles in order to show all of the misspellings of the word Sydney. This one query albeit not perfect resolved a lot of difficult conversations at the time and delighted a lot of users.
Managed ElasticSearch
Where we again caused some controversy was the proposal to use our own managed ElasticSearch cluster running on top of Elastic Container Service ECS. At the time AWS had its own managed ElasticSearch solution, so why would you want to do it yourself?
The problem with AWS’s solution at the time is that while AWS had 3 availability zones (AZ’s) in Sydney, only 2 of them were used by the ElasticSearch managed service. This meant that in the unlikely, but possible event of an AZ issue, the system would run in a degraded state. At the time it also had limited instance types, no scaling or monitoring was provided, and under load had performance issues.
Running it ourselves meant we could have the cluster running in all 3 AZ’s and in the event of a single region going now, the system would have no impact. It also allowed us freedom to chose whatever instance types best fit our loads and we could benefit
There was also one other benefit to this. We could use the leftover compute on the ECS cluster to run all the additional services that the solution would need. This being the backend API’s, serving the front end, content importers, data converters and the like. In effect, making the system “free” from a cost perspective, except for the search cluster which was needed anyway.
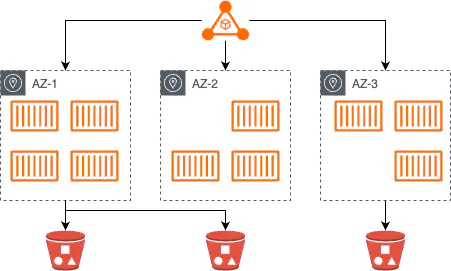
The design looked fairly similar to the above, with containers running on the cluster over the 3 AZ’s. The search cluster was running all the time in each AZ while background tasks the the API were evenly distributed where there was capacity.
Syncing the data from S3 into ElasticSearch was done in two ways. The first was when a record was added, updated or deleted. After saving the record to S3 it would then update ElasticSearch using a named key. The record would then be available and appear in search results. The second was a sync process ran every morning. It would iterate every file in S3 and update the ElasticSearch cluster. This was done for a few reasons. The main being the first initial load required it, but it also ensured that if there was a temporary problem writing into ElasticSearch so long as the data landed in S3 it would eventually sync in.
Further updates were made to this process to have a flag where it would only resync files updated in the last week to reduce the time to run, or allow a full sync where there was need.
File Imports
It was expected early on that CoDA would deal with large scale imports of both metadata and video and audio for that metadata.
For imports an early decision was made that all imports and exports to CoDA would be done through the use of S3 buckets rather than direct integration via API. The reasons for this were fairly simple.
- It ensured that nobody had to learn some new API’s or exotic ways to import content
- It solved all issues of scale as it suddenly became AWS’s problem
- It served as a nice intermediate point between CoDA and the external system using a common API
Partly this decision came as a result of the mass transcode process what was being done for some of the internal systems. That was being done through a third party, with AWS Snowball’s being used to ship content out. The results of this process landed in nominated S3 buckets and so we built on this idea.
This idea worked well, and was applied to every other integration the system had. This included ingesting additional content or media, exporting to 3rd party systems, or any other integration. While the initial API was designed to be used by other systems, this never happened, partly on the basis of how much easier it was to get people to work with S3.
CoDA’s own transcoding was directed to be done through the use of the ABC’s in house transcoder named metro. For our integration we would push files to be transcoded into a nominated S3 bucket with a specific filename format. Transcoded files would appear in a different S3 bucket, and using the filename we would be able to determine which record it belonged to and import it into the system. I was unable to find the original post about how this worked on the ABC blog, but I did find the following three links which explain it in some detail and are by some of the people who worked on it.
- https://nickmchardy.com/2019/04/my-favourite-project.html
- https://daphnechong.com/2015/12/09/metro-the-abcs-new-media-transcoding-pipeline/
- https://www.slideshare.net/slideshow/inside-the-abcs-new-media-transcoding-system-metro/59660422
The nice thing about this integration was that it fit in well with the established patterns of using S3 as our API layer, and as such allowed us to leverage all the existing code.
Storage Cost Optimization
A fairly common pattern when it comes to video files is to transcode from the master copies into multiple renditions, since transcoding on the fly is prohibitively expensive. CoDA was no exception with a proxy file being generated using metro for all content added.
Where there was a great saving was by transitioning all the master content into AWS’s cold storage solution glacier after 24 hours.
Use of Go
All the backend systems were written in Go. We had free reign of choice at the time, and while I was very familiar with Java chose Go over it. The main reason being the ABC was using it already, and I was willing to put the time in to learn Go. Having the application as a Go monorepo allowed us to have multiple entry points into the application using the common Go pattern as follows,
cmd
├── entry1
│ └── main.go
├── entry2
│ └── main.go
...
└── entry99
└── main.go
Which was especially useful as it meant we didn’t need to worry about breaking up applications service layer into specific importable submodules. This greatly sped up refactoring work, build times and developer sanity.
The other specific advantage we got out of it was by heavily leveraging go-routines. Due to the quantities of data we were throwing around lightweight go-routines made dealing with rewriting or moving millions of files fairly trivial. While this would have been just as possible in Java at the time using threads and queues, Go made it a lot easier, especially since a lot of these processes were only needed to run once.
A problem with Go
Go is a pretty neat language, but not without its flaws. One of which being C bindings. We knew we needed to resize images to smaller resolutions when displaying them in search results, as well as adding a watermark. The resize was simply to save on bandwidth and the watermark to ensure only the appropriate power users could use those images. Our first attempt was to do this on the fly in Go. However this proved to be far too slow given the display design we were working with which could easily request a hundred images for a single search.
While it worked in the development environments we observed it rapidly killing our containers which degraded the search service entirely required a deployment rollback.
The fix was to pre-process all the images and store the resized and watermarked images in a proxy file bucket. This process was still done using Go, but ran during the normal ingestion of content process ensuring no service degradation.
If you ever do need to do on the fly resizing I would suggest using something like Thumbor, which I know is far more capable for this.
Clipping
One of the non negotiable features was to allow users to make clips, allowing them to take small snippets of video or audio files. This was because some files were very large and someone on a regional internet connection might only need the last 5 minutes of a file. Since we were only taking clips, it worked out to be more cost effective to use EC2 instances with a large attached disk to download the file, use ffmpeg to extract just the bit required and then upload into S3.
We experimented with just downloading portions of the file out of S3 and using that, however it was unreliable, especially when it came to .mov files and would break more often than not. Thankfully T2/3 instance types in AWS have burst-able network capacity, and so downloads of very large files happened in an acceptable time.
The result of this was for the first version we used EC2 instances with a large disk volume attached so they could store the master file, and the resulting clip taken from it before uploading the latter into a different S3 bucket for the user to collect.
Random Cache Eviction
The clipping process as a scale out job which used ffmpeg to make clips of video files, was one of those things just crying out for performance improvements.
To speed it up I kept the downloaded files (which could be over 150 GB in size) as a local cache. Quite often during processing a clip is made of the same file, and so the system could avoid a redownload. The disk space the clippers had however was limited. When the disk was full (there was a separate disk for download and clip output) the process selected two of the downloaded files randomly and deleted the older one. It would then loop till there was enough disk space, or no files, and then process as normal.
Why was it random? It was due to having read about given no other information picking 2 elements randomly and evicting one that meets some criteria is a better strategy than nothing.
We did look at talking directly to S3 using ffmpeg, but this would not have allowed caching, and we found that for MOV files we needed to download most of the file anyway in order for ffmpeg to work correctly so this was not a great option.
In terms of times, the average time to process a clip using this process worked out to be under 5 minutes so far. Most of the clips were being made from 300 GB files and from our logging the cache is was working quite well and had saved over 200 S3 fetches over the course of a week.
You can observe a very old cloudwatch report showing how the clippers reacted with this change.
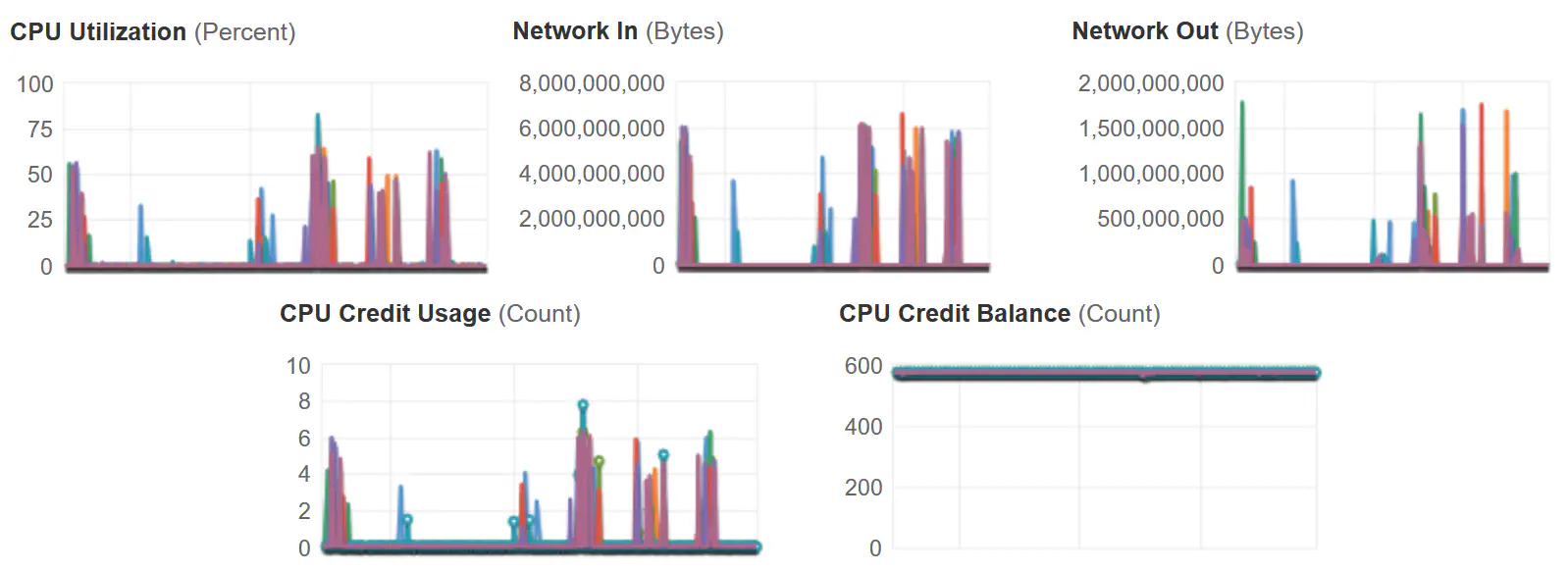
This process has since been improved by mounting S3 directly against the clipper instances for even more performance gains, and the deletion of a lot of code, including sadly the random cache eviction algorithm. I haven’t had access to the source for a long time, but a quick go-pseudocode implementation of the algorithm is included below. In theory adding 5 or more random choices could yield better results, similar to how Redis/Valkey expires keys.
func ClearSpace(dir string, freeSpace uint64, requiredSpace uint64) error {
for freeSpace < requiredSpace {
fl, err := os.ReadDir(dir)
if err != nil {
return err
}
if len(fl) == 0 {
return errors.New("not enough disk space")
}
one := fl[rand.Intn(len(fl))]
two := fl[rand.Intn(len(fl))]
if one.ModTime() <= two.ModTime() {
os.Remove(one))
freeSpace += one.Size()
} else {
os.Remove(two.Name())
freeSpace += two.Size()
}
}
return nil
}
The Transcoding is Broken
One of the more interesting stories was one day when I was asked to investigate the system, as no video or audio had finished transcoding. I had a quick look and noticed nothing unusual beyond that the transcoder was not returning any files and escalated it to the transcoder team.
What had happened was someone had been digitizing tape and pushed through a huge amount of 700 GB high resolution videos all at once. This was bogging down the transcoder system, which was unable to scale to meet the demand. The only solution offered was to just wait for the backlog to clear which took several hours. After which all future transcodes worked within expected timeframes.
We ended up adding some well placed logs to highlight this sort of information in the future, and I believe that the transcoder system was modified to scale up a lot more given that CoDA was its primary source of load at the time.
What would I change?
In hindsight I think we made absolutely the correct calls on the tech stack and architecture. The fact that CoDA has been built on and expanded without any large changes is supports this. So given the time over again I think I would do this pretty much the same.
The system underwent a Well Architected Review (WAR) from AWS and came out very well from it. So well in fact that there were only a few minor things that came out of the process. The AWS reviewer was impressed with the result. What helped a lot was that the system was designed to degrade gracefully. In fact it could withstand a a single to multi AZ outage in AWS, with no loss of data or functionality. Even if individual components were to fail entirely, the system would limp on and recover once those dependant systems did.
Were I to start to today however I would change a few things, mostly to leverage new AWS functionality.
The first being I would run the API’s for it using Lambda and API Gateway. At the time private API Gateway’s did not exist in AWS hence the decision to not use them. I would also probably move to a manged search solution as all of the issues we dealt with have since been resolved. For backend import and processing services, since they ran ad-hoc anyway they could be moved to fargate. This would probably keep the costs when running similar to the current setup where the compute effectively for free. I still think they would be slightly higher, but so much as to make the internal cost of running an ECS cluster worth it again.
That said, I still rate CoDA as one of the more interesting projects I have ever worked on. I am very thankful for the trust given to myself and the team that worked on CoDA and still to date consider it one of the most successful projects I have been involved with.