Optical character recognition with Amazon Textract

Table of Contents
Last year at AWS re:Invent, Amazon Textract was announced as a next-generation OCR service which not only performs word-based translation, but can also provide form and table value extractions in a way that makes it easy for developers to link into their own services. Today marks its Generally Available release.
Optical character recognition (OCR) has always been a challenging problem to solve. The technology to do this has been around since 1914, yet some companies still employee a human workforce to perform laborious data entry from forms and documents into their corporate systems. Textract aims to automate this problem however it does not currently support handwriting within the documents.
Form and Table Support
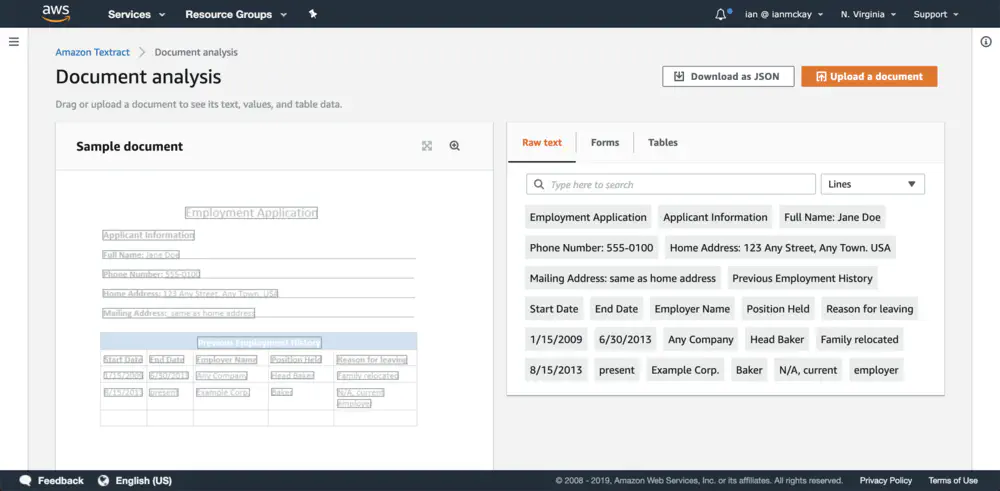
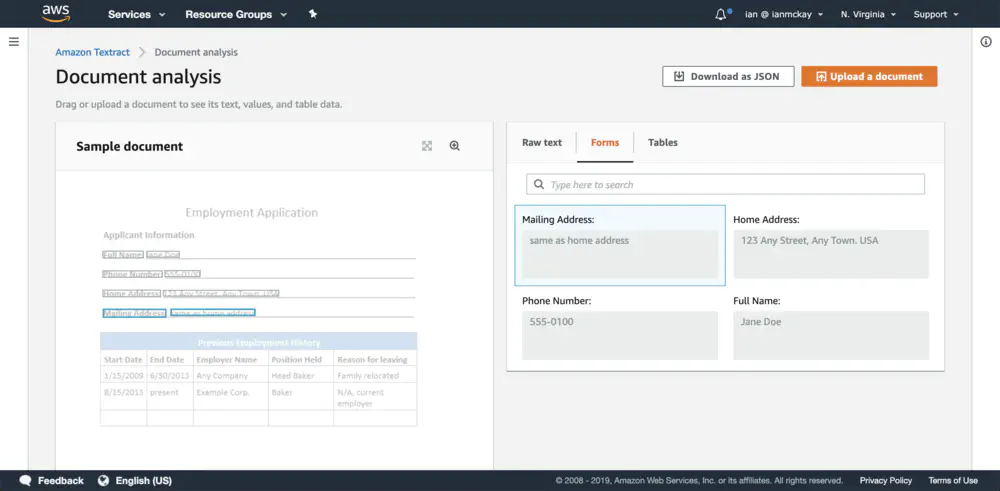
In addition to word and line text extraction, form and table support is something that is rare to OCR technologies and even rarer to have it available as programmatically extractable information. Oddly, paragraph support is not present in the service.
Form information is available in API call responses as a key-value set and table information is available as cell blocks with row / column values and cell spanning information. All values regardless of type include bounding box coordinates (which is shown in the console demo screenshots) and confidence scores.
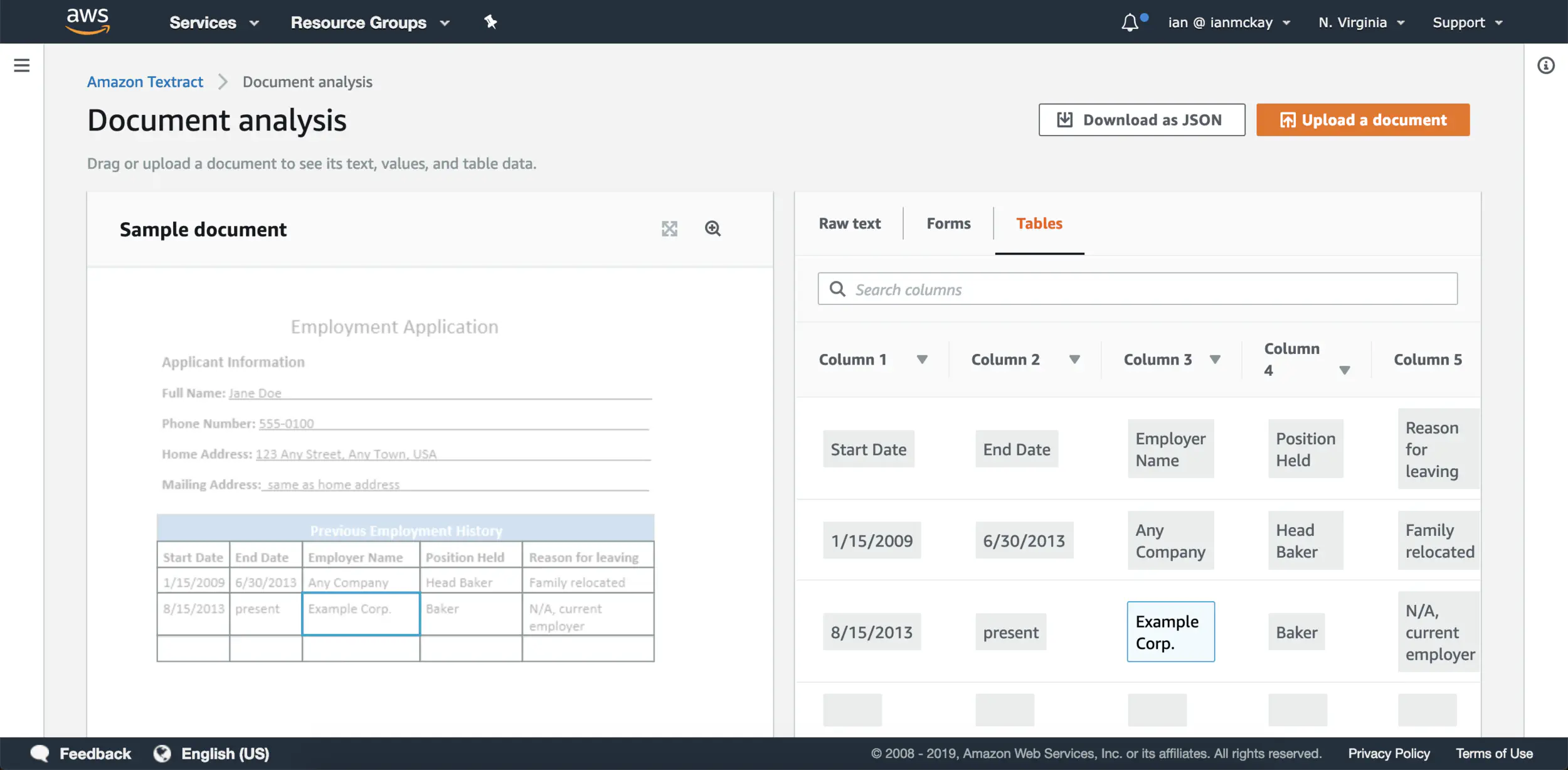
Testing The Limits
As with most services, the demo document is the best case scenario so I wanted to test with something unknown to see how well it did, using a document I had readily available. Here’s how it did:
{kind=link}
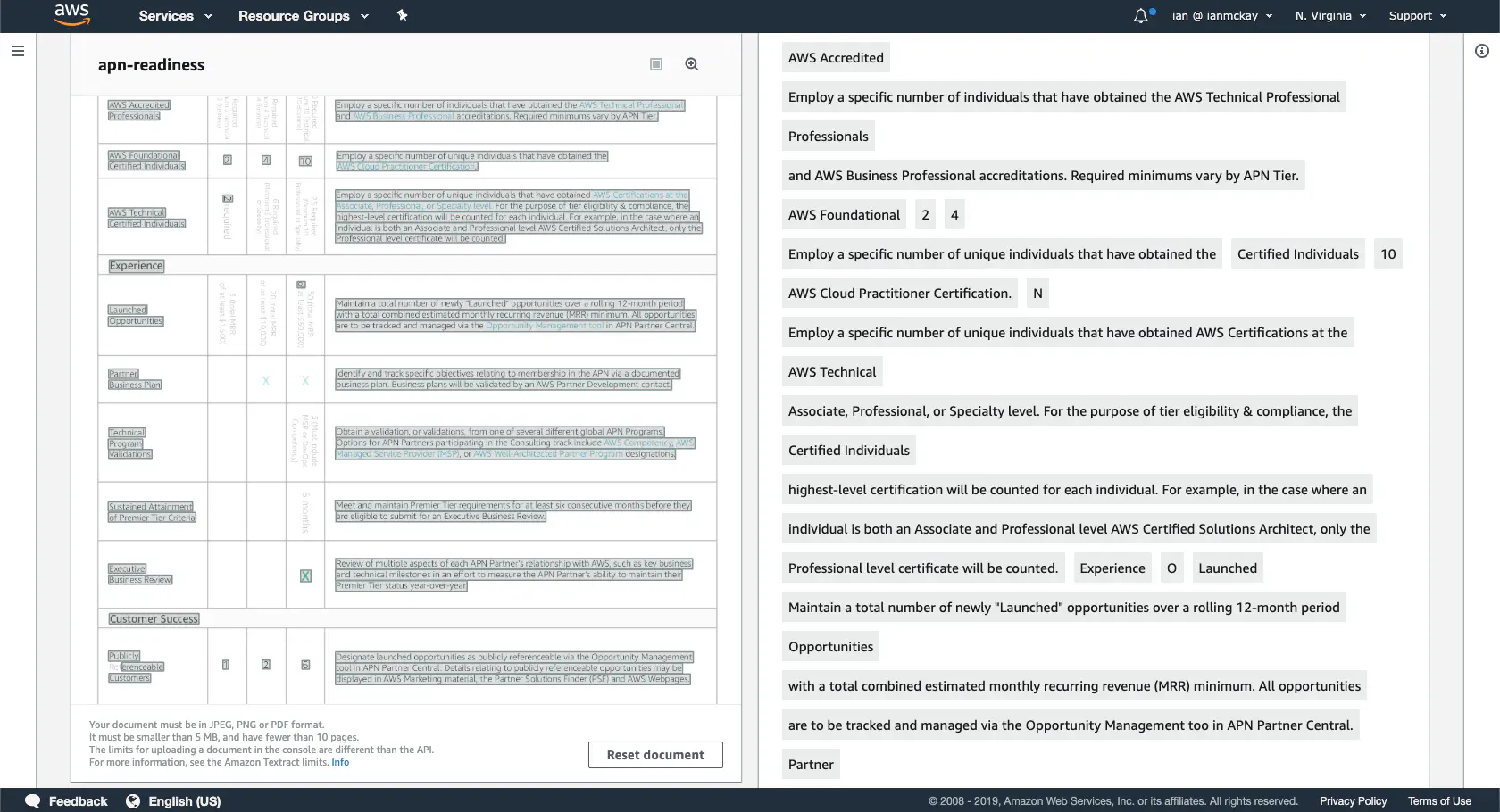
From the screenshot you can see it did fairly well, though it did have some issues:
- 90° Rotated Text Not Detected: One of the limitations of the service is that it only supports horizontally aligned text, so the text in this was not found correctly.
- Multiple ‘X’ checks were not discovered: Though it correctly detected one checkmark (as the text ‘X’), it missed two in the same format immediately above it.
- Did not detect single-row or single-column tables: In our testing with other documents, tables with a single row or single column were not detected as tables.
Pricing and Availability
Textract is marketed as costing $1.50 per 1000 pages, but it’s important to note that’s only for simple text recognition. If you want to detect table data, that price goes up 10x to $15 per 1000 pages and if you add form data the total becomes $65 per 1000 pages, a 43x increase!
As of today, the service has become generally available in the N. Virginia, Oregon, Ohio and Ireland regions. The service is expected to roll out to all commercial regions gradually as they improve the service.
TL;DR
Amazon Textract is a remarkable step up for OCR technologies. It exceeds competition such as the Google-sponsored Terreract project but costs can jump steeply when adding advanced features such as table and form information extraction.
If you’d like help designing an automated document scanning system, get in touch with us to find out how we can help you plan, design or build your solution.